为挖掘量子信息领域潜在人才,让量子教育惠及更多群体,促进量子科技人才梯队储备,由深圳计算机学会、香港电脑教育学会、澳门电脑学会主办,深圳计算机学会量子信息专委会、量旋科技、哈工大(深圳)协办,联合创办了专门针对量子计算算法编程的全国性赛事——“量旋杯”大湾区量子计算挑战赛。
从2021年开始,“量旋杯”已成功举办两届,吸引了大湾区乃至全国众多学生群体和量子计算爱好者参加。


第二届“量旋杯”量子计算挑战营顺利举行,助推量子科技人才培育
2024年4月27日,第三届“量旋杯”大湾区量子计算挑战赛正式宣布启动,吸引了众多业界人士和新闻媒体的关注。本届量旋杯共分三大赛道:普及组、公开组和量子国际象棋组。
值得一提的是,今年的“量旋杯”已经升级为国际化赛事。其中,面向海内外量子计算爱好者和专业学生,特别设置“公开组”和“量子国际象棋”赛道,旨在提供一个全球化的知识交流与竞技平台。
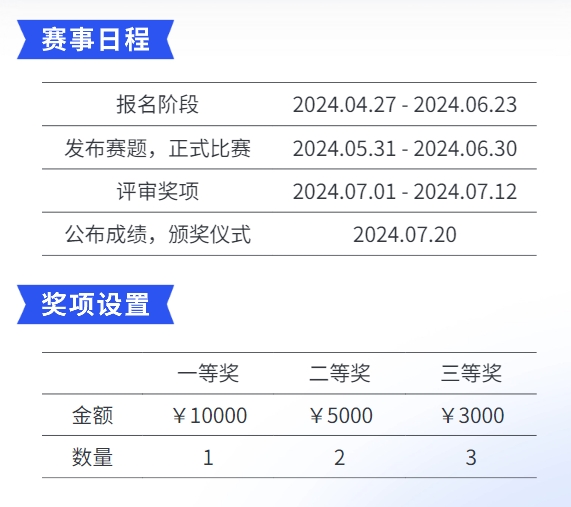
“公开组”赛道
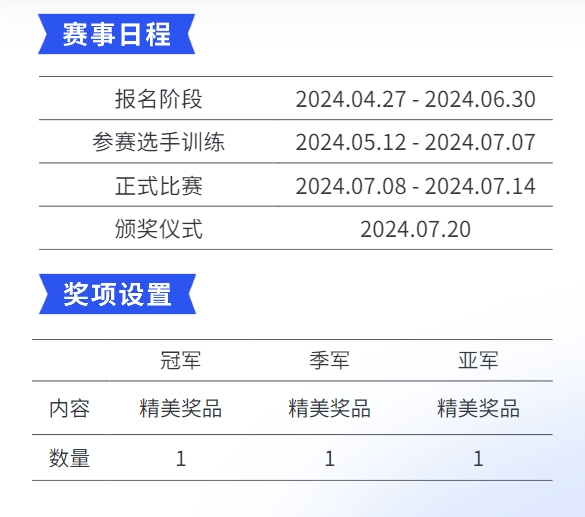
“量子国际象棋组”赛道
为通过以赛促学形式,推进量子技术普及,本届“量旋杯”将进行系列校园巡讲活动,来到大湾区学校内部,以线下实地交流的方式,吸引更多学生进入到量子计算的世界里来。欢迎点击文末“阅读原文”或下方海报右侧二维码报名参赛!
作为大湾区典型的高校代表,深圳大学一直以来都很重视前沿学科的发展,尤其是物理与光电工程学院,很早就看到量子计算学科的重要性,并且已经开设了量子计算课程。
5月27日,“量旋杯”校园巡讲第一站,我们就将走进深圳大学,给全校师生带来一场深度交流的机会,同时在现场为大家进行“公开组”赛道的介绍和问题答疑。

本次宣讲中,我们邀请的讲师将分享量子计算行业的最新进展,让大家更为深入了解这一领域的技术前沿、政策动态及广阔的产业前景,同时也会重点围绕量旋杯公开组的赛道赛制和规则进行解读,帮助大家了解大赛评分标准和评审维度,在比赛中充分展示自身实力,摘取荣誉奖项。
在公开组的正式比赛中,参赛选手将解决一系列涉及量子编程、量子算法设计等领域的挑战性问题,这些问题旨在考察选手对量子计算的深度理解和解决问题的创新思维。
在校园宣讲活动现场,我们特别邀请到专业讲师,对比赛的代表性样题进行细致讲解,帮助大家快速了解大赛的命题方向。
我们相信,通过样题讲解和赛制交流,将能够帮助大家在正式比赛中充分应用自身的专业知识和经验,展现出技巧与才华。
【样题题目】
设计量子算法解决基于 De Bruijn Graph 的基因组组装中的重复片段问题。
【样题背景】
在现代生物技术的发展过程中,高通量测序技术已经成为获取大规模基因数据的主要手段。然而,由于当前技术的局限性,直接获取完整的基因序列仍然具有挑战性。实际上,我们通常会得到大量的较短的基因片段(也被称为reads),这些reads需要通过某种方式进行拼接,以重建出原始的基因序列。
德布鲁因图(De Bruijn Graph, DBG)算法是一种常用的从头拼接(de novo genome assembly)算法之一。DBG算法利用图论来处理序列数据,特别是处理基因测序生成的短片段(reads)的问题。给定一系列长度为k的字符串(被称为k-mers),DBG算法构造一个有向图,其中每个节点表示一个唯一的(k-1)-mer,每条有向边表示一个k-mer。
其算法组装流程如下:
通过这些步骤,我们可以构建出一个De Bruijn图,该图捕获了原始序列中的所有k-mer的重叠关系。在理想的情况下,我们可以通过寻找这个图中的欧拉路径(即访问每条边一次且仅一次的路径)来重建原始序列。
然而,在实际的组装过程中,由于测序错误和重复基因片段等问题,德布鲁因图通常会更复杂。
测序错误:由于测序技术的误差,reads可能包含一些错误,例如插入、删除或替换等。这些错误可以引入不存在于真实基因组中的k-mers,从而在DBG中产生错误的边和节点。如图1所示,read3中的胞嘧啶“C”被错误测序为鸟嘌呤“G”,此时DBG中产生错误的边和节点。
处理这种情况的一种策略,是利用每个k-mer在所有reads中出现的次数来定义每条边的权重。直观上,如果一个k-mer在许多reads中多次出现,那么我们可以相对比较有信心地认为,这个k-mer存在于真实的基因组中。反之,如果一个k-mer只在很少的reads中出现,或者只出现了一次,那么这个k-mer很可能是由于测序错误引入的。
根据这个策略,我们可以定义一个优化问题,即寻找一条路径,使得经过的边的权重和的绝对值最大。这条路径将代表我们组装出的基因序列。
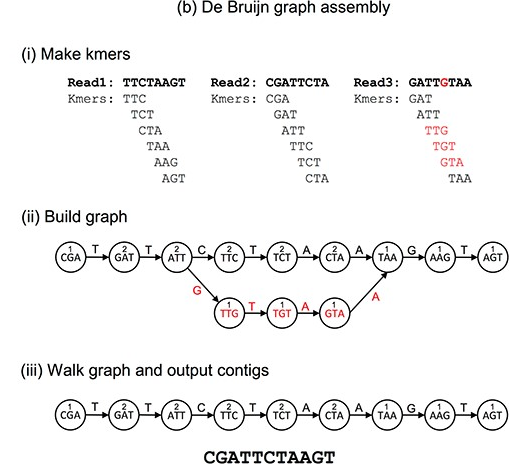
图1:DBG算法组装流程(测序错误)
重复片段:许多生物的基因组中都存在大量的重复序列。由于这些重复序列完全相同,我们无法确定reads来自哪个重复区域。如图2中的序列“ATTC”出现了三次,正常的情况下,我们无法确定一个包含“ATTC”的read到底来自于第一次出现的位置、第二次出现的位置还是第三次出现的位置。
为了解决这个问题,一种可能的策略是利用三代测序技术(Third-generation sequencing)。相比于二代测序技术(Second-generation sequencing),三代测序技术可以生成更长的reads。这意味着,每个read能够覆盖更多的基因信息,包括位于重复序列前后的唯一序列。
通过这种方式,我们可以得到足够的上下文信息,从而有可能确定read的来源。在组合优化问题中,可以将上下文信息转为奖励项权重,如测序得到read为“GATTCC”,则可以确定“ATTC”的read来自于第一次出现的位置并分配一个绝对值更大的权重值,最后通过找到权重和绝对值最大的路径代表我们组装出的基因序列。
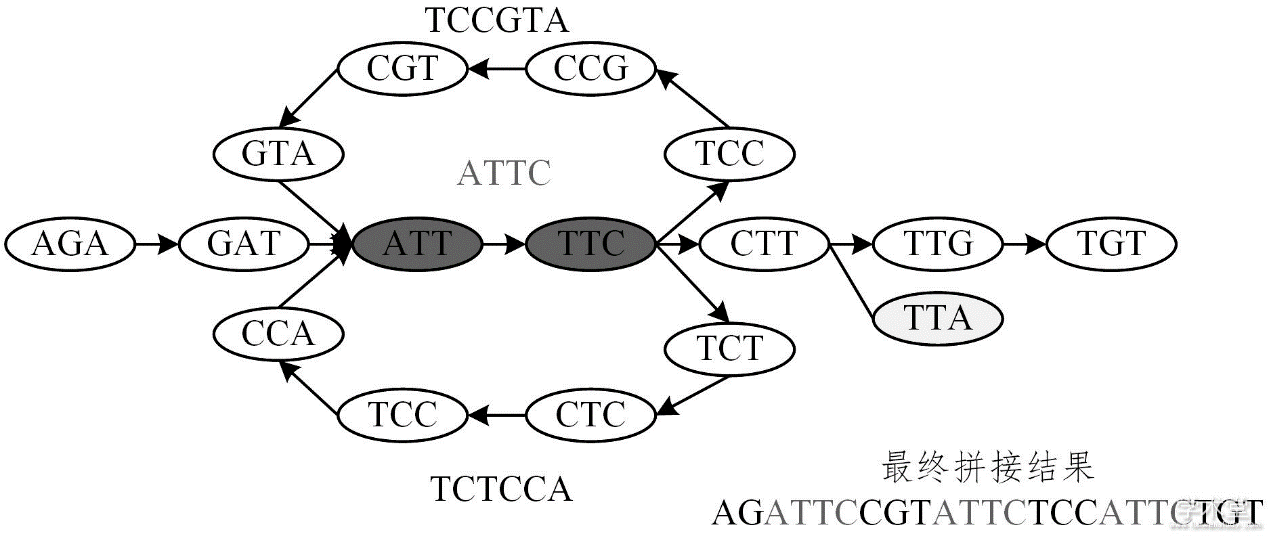
图2:存在重复片段的De Bruijn图及拼接结果
【样题要求】
请设计一个合适的量子算法将模型(如图3所示)进行正确组装。
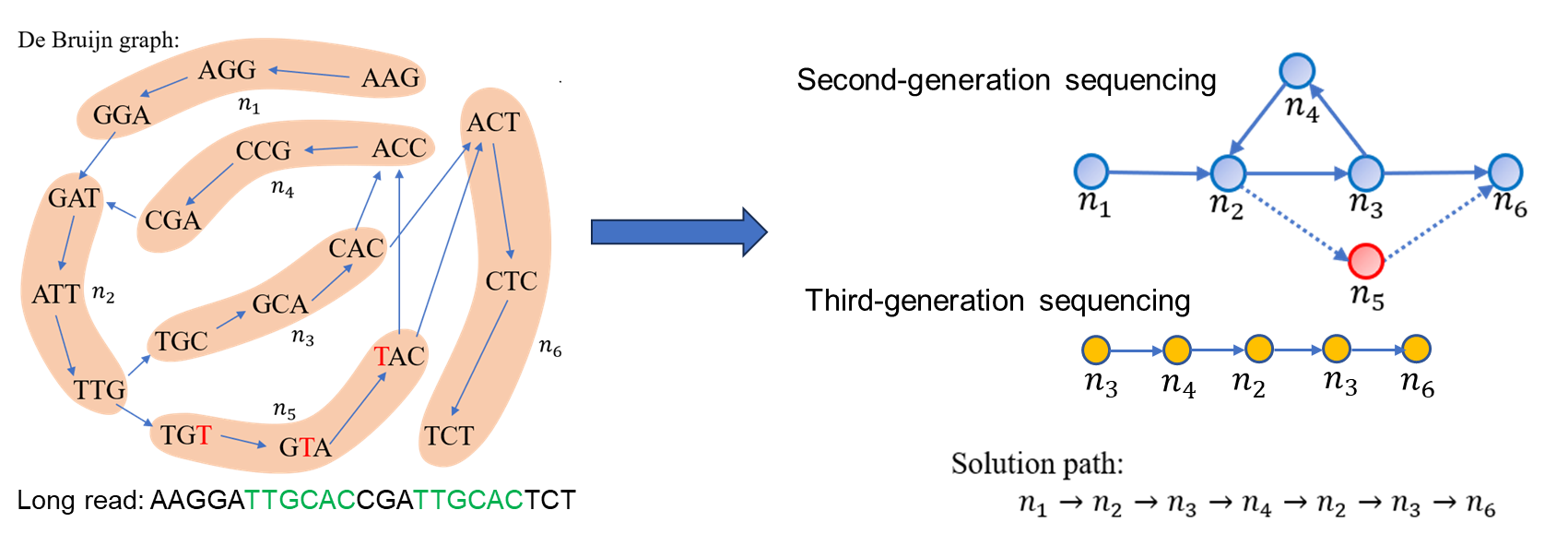
图3:左图为存在重复片段的德布鲁因图及拼接结果。其中重复片段为“TTGCAC”,测序错误的read为“TGTAC”。右图是德布鲁因图的简单示意图及组装路径。
【解题思路】
在该问题中,目标函数可以写为: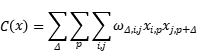
其中二进制变量x_i,p表示在第P步是否选择第i个节点;ω_Δ,i,j表示相隔Δ步的第i个节点和第j个节点的权重值。需要注意的是,为了保证最终的组装路径包含重复节点,p的值一定要远大于节点数n。
其限制条件为,从头组装算法要求第一步选择的节点有且只有一个, ![]()
每一步选择的节点至多为1,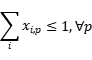
为了确保我们得到的基因序列是一个连续的路径,若在第p步不选择任何节点,则第p+1步一定不选择任何节点,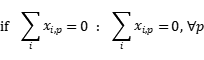
将目标函数和限制条件进行结合,通过引入合适的惩罚系数λ₁λ₂,将其构建为一个无约束二次二进制优化问题(Quadratic Unconstrained Binary Optimization,QUBO)。![]()
在这里,可以将限制条件2和3进行结合形成限制函数C₂。其中,
![]()
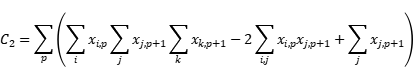
【参考文献】
[1] J.-K. Fang, Y.-F. Lin, J.-H. Huang, Y. Chen, G.-M. Fan, Y. Sun, G. Feng, C. Guo, T. Meng, Y. Zhang, X. Xu, J. Xiang, and Y. Li, PRX Life 2, 023006 (2024).
目前,“量旋杯”校园巡讲活动火热进行中,欢迎各学校与我们联系交流!
 京公网安备11011402054247号
京公网安备11011402054247号
非常抱歉!本站不支持旧版本IE浏览器~~建议使用IE10/IE11/Chrome/Firefox/Safari等高级浏览器浏览。


